Online English Dictionary
A Simple Knowledgebase
• ADS
• CSS
• EXCEL
• SCRIPTS
• SEO
• WEBSITE-MONITORING-AND-BACKUP
WEB-SERVER | WEB-CACHE | NGINX-CACHE
What is Web Cache? Why do people use them?
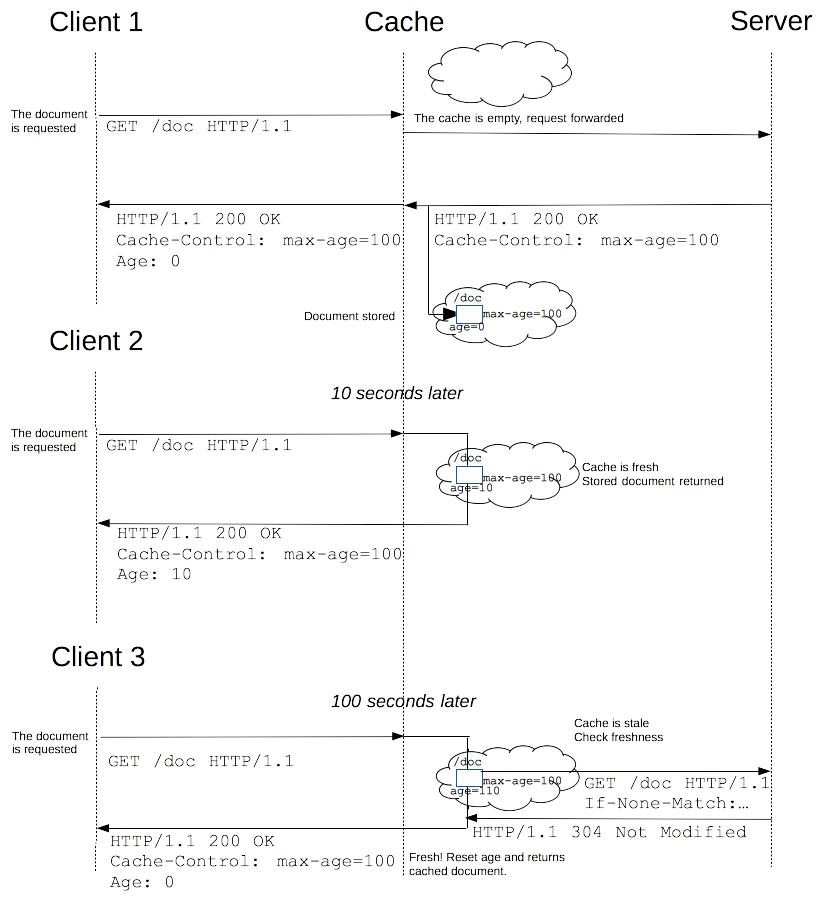
A Web cache sits between one or more Web servers (also known as origin servers) and a client or many clients, and watches requests come by, saving copies of the responses - like HTML pages, images and files (collectively known as representations) - for itself. Then, if there is another request for the same URL, it can use the response that it has, instead of asking the origin server for it again.
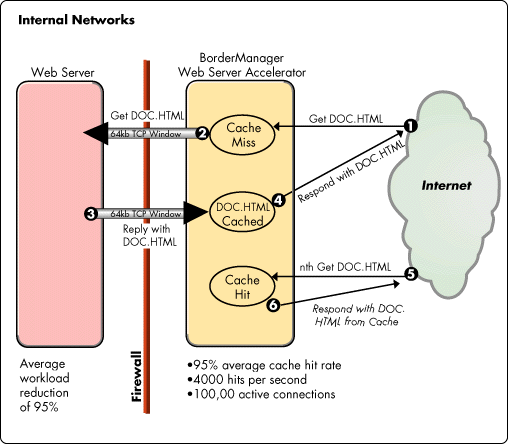
A Web cache is a dedicated computer system which will monitor the object requests and stores objects as it retrieves them from the server. On subsequent requests the cache will deliver objects from its storage rather than passing the request to the origin server. Every web object changes over time and therefore has a useful life or "freshness". If the freshness of an object expires it is the responsibility of the Web cache to get the new version of the object.
Fetching something over the network is both slow and expensive. Large responses require many roundtrips between the client and server, which delays when they are available and when the browser can process them, and also incurs data costs for the visitor. As a result, the ability to cache and reuse previously fetched resources is a critical aspect of optimizing for performance. The good news is that every browser ships with an implementation of an HTTP cache. All you need to do is ensure that each server response provides the correct HTTP header directives to instruct the browser on when and for how long the browser can cache the response.
Kinds of Web Caches
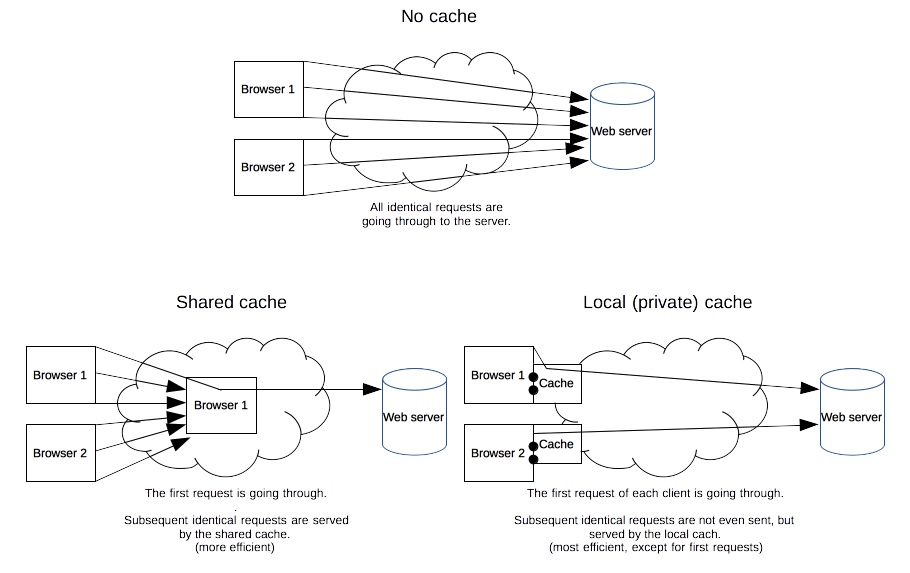
- (private) Browser Caches - If you examine the preferences dialog of any modern Web browser (like Internet Explorer, Safari or Mozilla), you'll probably notice a "cache" setting. This lets you set aside a section of your computer's hard disk to store representations that you've seen, just for you. The browser cache works according to fairly simple rules. It will check to make sure that the representations are fresh, usually once a session (that is, the once in the current invocation of the browser).
- (shared) Proxy Caches - Web proxy caches work on the same principle, but a much larger scale. Proxies serve hundreds or thousands of users in the same way. Because proxy caches aren't part of the client or the origin server, but instead are out on the network, requests have to be routed to them somehow. Proxy caches are a type of shared cache; rather than just having one person using them, they usually have a large number of users, and because of this they are very good at reducing latency and network traffic. That's because popular representations are reused a number of times.
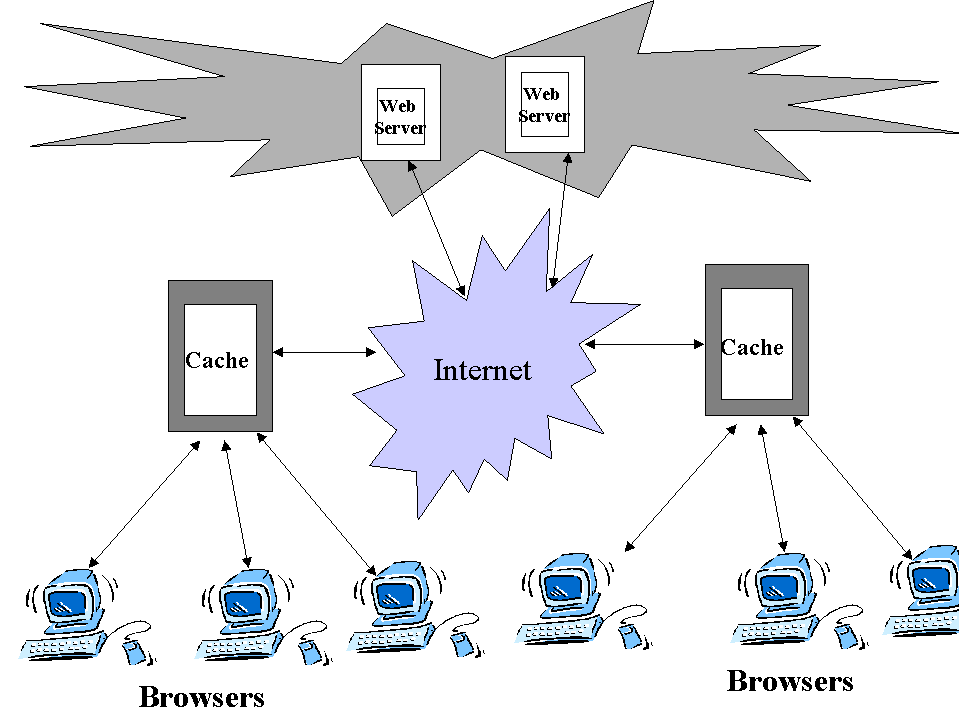
A web cache sits in between a client and an "origin server", and saves copies of all the content it sees. If a client requests content that the cache has stored, it returns the content directly without contacting the origin server. This improves performance as the web cache is closer to the client, and more efficiently uses the application servers because they don't have to do the work of generating pages from scratch each time.
Nginx is a very capable web cache. While Varnish is a pure web cache with more advanced cache-specific features than Nginx, NGINX is also deployed as a reverse proxy or load balancer and has a full set of caching features.
Controlling Cache
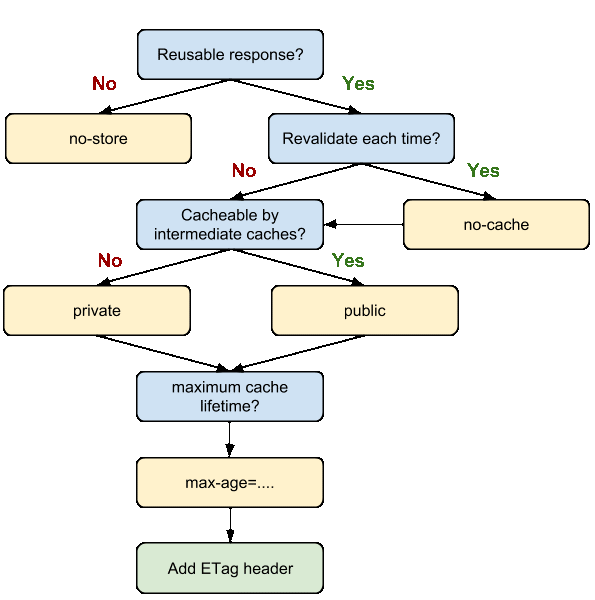
The Cache-Control HTTP/1.1 general-header field is used to specify directives for caching mechanisms in both requests and responses. Use this header to define your caching policies with the variety of directives it provides. It defines the amount of time and manner a file is to be cached.
Cache request directives - Standard Cache-Control directives that can be used by the client in an HTTP request.
Cache-Control: max-age=<seconds> Cache-Control: no-cache Cache-Control: no-store
Cache response directives - Standard Cache-Control directives that can be used by the (origin) server in an HTTP response.
Cache-Control: must-revalidate Cache-Control: no-cache Cache-Control: no-store Cache-Control: public Cache-Control: private Cache-Control: proxy-revalidate Cache-Control: max-age=<seconds>
- Cache-Control: no-cache, no-store - The cache should not store anything about the client request or server response. A request is sent to the server and a full response is downloaded each and every time. The "no-store" response directive indicates that a cache MUST NOT store any part of either the immediate request or response. This directive applies to both private and shared caches.
- Cache-Control: public - The public directive indicates that the response may be cached by any cache. This can be useful, if pages with HTTP authentication that aren't normally cacheable, should now be cached.
- Cache-Control: private - The private directive indicates that the response is intended for a single user only and must not be stored by a shared cache.
- Cache-Control: max-age=31536000 - The most important directive here is "max-age=<seconds>" which the maximum amount of time a resource will be considered fresh, i.e. "max-age" defines the amount of time (in seconds) a file should be cached for. This directive indicates that the response is to be considered stale after its age is greater than the specified number of seconds. For the files in the application that will not change, you can usually add aggressive caching. This includes static files such as images, CSS files and JavaScript files.
- Cache-Control: must-revalidate - When using the "must-revalidate" directive, the cache must verify the status of the stale resources before using it and expired ones should not be used.
- Pragma: no-cache (or) public - Pragma is a HTTP/1.0 header, is not specified for HTTP responses and is therefore not a reliable replacement for the general HTTP/1.1 Cache-Control header, although it does behave the same as Cache-Control. It is used for backwards compatibility with HTTP/1.0 caches where the Cache-Control HTTP/1.1 header is not yet present.
Freshness of cached contents
Once a resource is stored in a cache, it could theoretically be served by the cache forever. Caches have finite storage so items are periodically removed from storage. This process is called cache eviction. As HTTP is a client-server protocol, servers can't contact caches and clients when a resource change; they have to communicate an expiration time for the resource. Before this expiration time, the resource is fresh; after its expiration time, the resource is stale. Note that a stale resource is not evicted or ignored; when the cache receives a request for a stale resource, it forwards this requests with If-None-Match to check if it isn't in fact still fresh. If so, the server returns a 304 (Not Modified) header without sending the body of the requested resource, saving some bandwidth.
HTTP ETag
The ETag or entity tag is part of HTTP that provides web cache validation, allowing a client to make conditional requests. This allows caches to be more efficient, and saves bandwidth, as a web server does not need to send a full response if the content has not changed.
ETag generation - The use of ETags in the HTTP header is optional. The method by which ETags are generated has never been specified in the HTTP specification. Common methods of ETag generation include using a collision-resistant hash function of the resource's content (i.e., a hash of the last modification timestamp) or simply just a revision number.
Types of ETag - The ETag mechanism supports both strong validation and weak validation. They are distinguished by the presence of an initial "W/" in the ETag identifier.
"123456789" - A strong ETag validator W/"123456789" - A weak ETag validatorThe difference between a regular (strong) ETag and a weak ETag is that a matching strong ETag guarantees the file is byte-for-byte identical, whereas a matching weak ETag indicates that the content is semantically the same. So if the content of the file changes, the weak ETag should change as well.
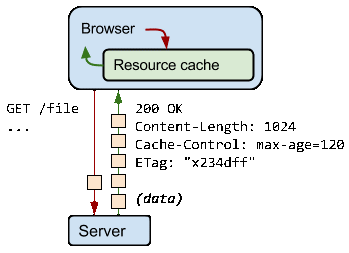
When the server returns a response, it also emits a collection of HTTP headers, describing its content-type, length, caching directives, validation token, and more. For example, in the above exchange, the server returns a 1024-byte response, instructs the client to cache it for up to 120 seconds, and provides a validation token ("x234dff") that can be used after the response has expired to check if the resource has been modified.
Assume that 120 seconds have passed since the initial fetch and the browser has initiated a new request for the same resource. First, the browser checks the local cache and finds the previous response. Unfortunately, the browser can't use the previous response because the response has now expired. At this point, the browser could dispatch a new request and fetch the new full response. However, that's inefficient because if the resource hasn't changed, then there's no reason to download the same information that's already in cache!
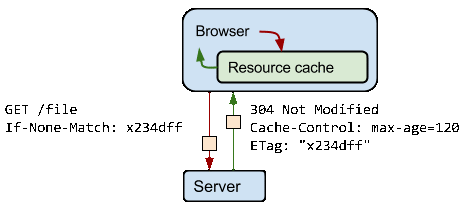
That's the problem that validation tokens, as specified in the ETag header, are designed to solve. The server generates and returns an arbitrary token, which is typically a hash or some other fingerprint of the contents of the file. If the fingerprint is still the same, then the resource hasn't changed and you can skip the download.
In the preceding example, the client automatically provides the ETag token in the "If-None-Match" HTTP request header. The server checks the token against the current resource. If the token hasn't changed, the server returns a "304 Not Modified" response, which tells the browser that the response it has in cache hasn't changed and can be renewed for another 120 seconds. Note that you don't have to download the response again, which saves time and bandwidth.